We present MLZero, a multi-agent system that automates
end-to-end solutions for multimodal ML tasks. Given input data $x$ and optional user inputs
$U_{\text{opt}}$, the system produces solutions including predicted outputs $y$, code
artifacts $C$, and execution logs $L$:
$\mathcal{F}(x, U^{\text{opt}}) = (y, C, L)$.
Our ML model building process for various tasks is achieved by generating code employing different ML
libraries and executing it. For supervised learning tasks, $x$ typically includes labeled training data,
unlabeled test data, and a brief task description or instruction. For zero-shot tasks, $x$ would simply
consist of unlabeled test data and the task description. Through this comprehensive system, MLZero effectively bridges the gap between noisy raw
data inputs and sophisticated ML solutions, providing a truly end-to-end automated ML framework adaptive
to any modalities.
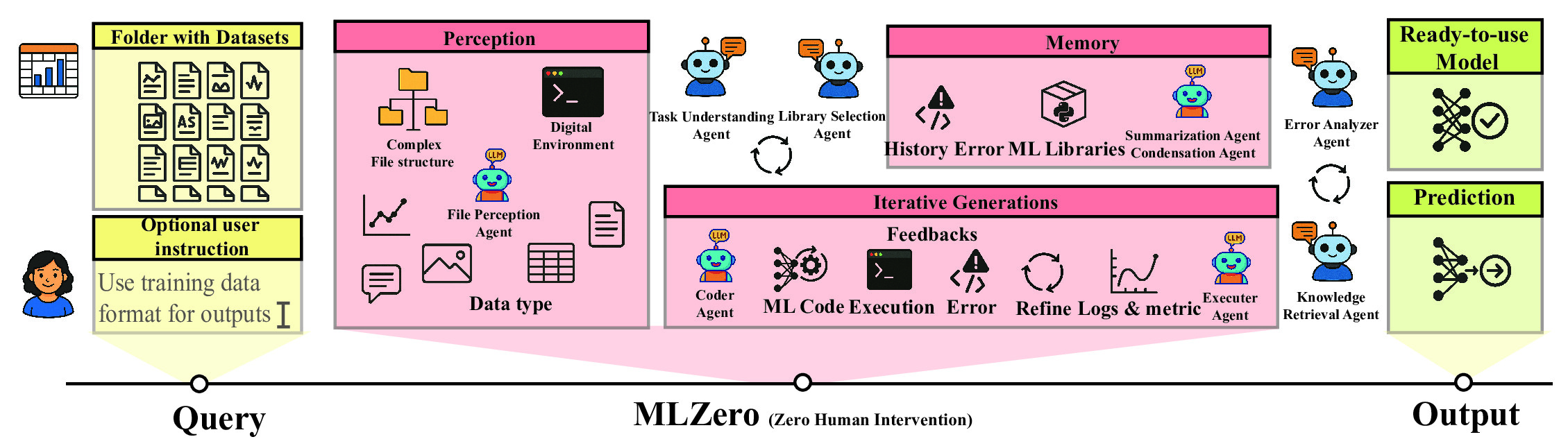
Our system comprises four modules, where each module is a subsystem with one or more agents, and each
agent is a specialized LLM augmented with utility functions: (1) Perception that interprets
arbitrary data inputs and transforms them into structured context; (2) Semantic Memory that
enriches the system with knowledge of the ML Library; (3) Episodic Memory that maintains
chronological execution records for targeted debugging; and (4) Iterative Coding that implements
a refinement process with feedback loops and augmented memory.
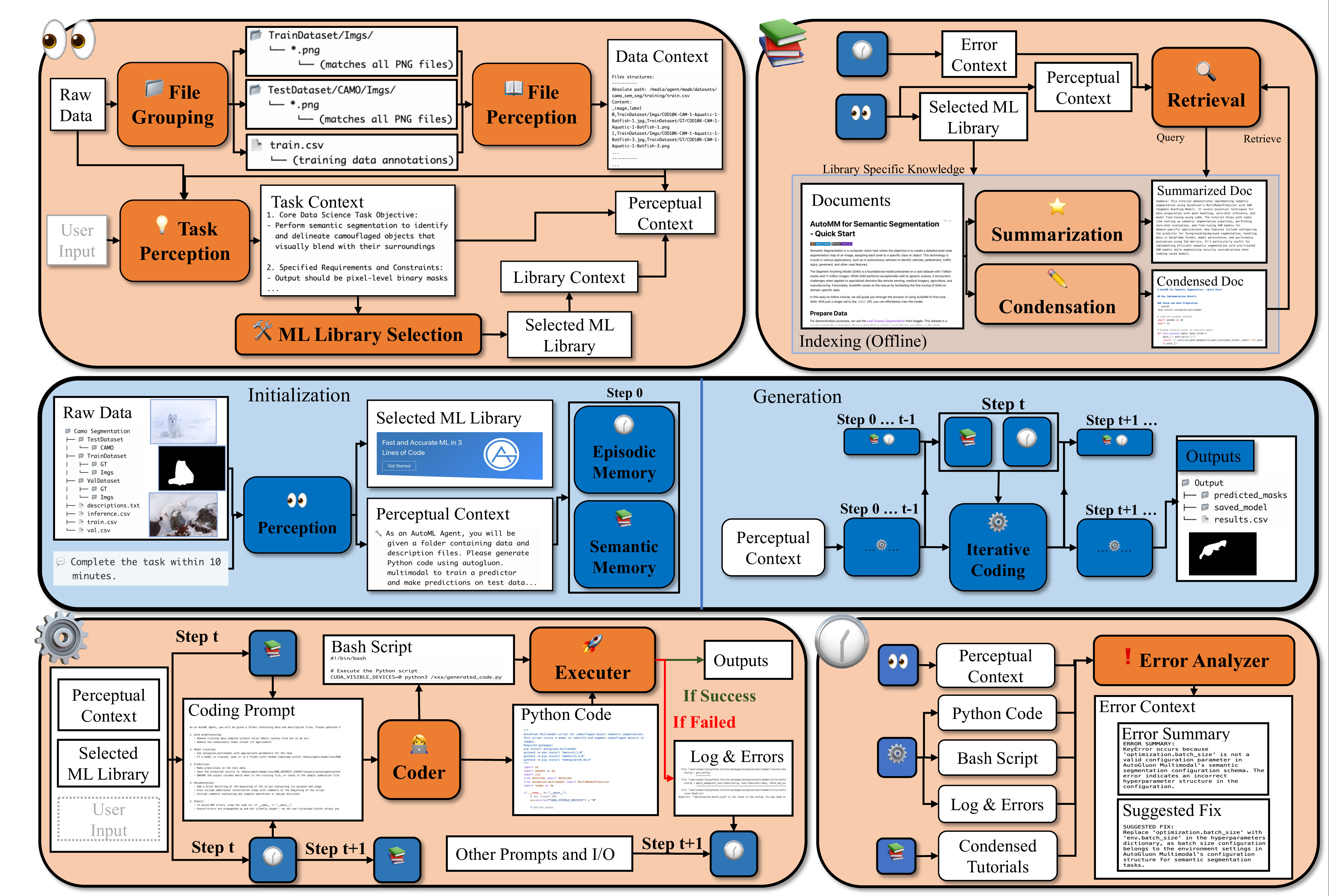
The Perception module $\mathcal{P}$ acts as the cognitive lens of the system, orchestrating the
transformation of various data inputs into actionable ML workflow specifications:
$\mathcal{P}(x, U^{\text{opt}}) = (P, M)$.
This module consists of three agents: the File grouping and file perception agent performs structural
analysis of raw data $x$, grouping similar files and interpreting file contents; the Task perception agent
extracts semantic information from raw data, derived context, and user input $U_{\text{opt}}$ to identify
objectives, constraints, and evaluation criteria; and the ML Library selection agent employs context-aware
reasoning to match problem characteristics with the appropriate ML Library $M$.
The Semantic Memory Module $\mathcal{S}_t$ enhances the LLM's parametric knowledge with domain-specific
information from external knowledge bases at each iteration $t$. These knowledge bases are constructed
offline by two agents: the summarization agent compresses relevant knowledge into concise paragraphs
serving as queryable indices, while the condensation agent transforms this knowledge into precise
and streamlined guidance. At each iteration $t$, given the error context $R_t$, the Semantic Memory Module
processes this information through its retrieval agent to query the knowledge base of the selected
ML library $M$, extracting condensed information $G_t$:
$\mathcal{S}_t(P, M, R_t) = G_t$.
The Episodic Memory module, $\mathcal{E}_t$, enhances the success rate of MLZero in ML model building by providing error
context $R_t$ at each iteration $t$ leveraging its chronological record of the system execution history:
$\mathcal{E}_t(P, C_{t-1}, L_{t-1}, G_{t-1}, R_{t-1}) = R_t$.
This component is initialized with the perception context $P$ and progressively stores the interaction data
at each iteration. When invoked during code generation, the error analyzer agent distills encountered
issues and contexts into concise error summaries paired with fix suggestions, enabling subsequent coding agents
to efficiently address specific problems without processing excessive contextual information.
With the support of components above, our system enters an iterative coding process $\mathcal{G}_t$, where
at each iteration $t$ it refines the solution based on execution feedback:
$\mathcal{G}_t(P, U^{\text{opt}}_t, R_t, G_t) = (y_t, C_t, L_t)$.
For each iteration $t$, the system first combines the perceptual context $P$, optional user input
$U^{\text{opt}}_t$, error context $R_t$, and the retrieved knowledge $G_t$ to guide the coder agent
in producing executable code $C_t$. The system then executes the generated code in a configured environment,
capturing logs $L_t$ and stores the model output $y_t$. The executer agent analyzes these results and
logs to determine the next steps: finalizing output upon success or identifying errors and initiating the next
coding iteration.